

For better or worse, Artificial Intelligence (AI) is here to stay. Algorithms are gathering and processing information about us all the time from our taste in clothes and music to spending habits and health.
How the algorithm knows you - an introduction to decision trees for machine learning
Machine learning is extremely useful. Algorithms can efficiently sell us products we want, offer content and entertainment in line with our interests and help banks, governments and medical practitioners make better informed decisions.
But how exactly do they work? And what are the risks we run surrendering decisions to machines?
Dr Sam Kirshner, Senior Lecturer in the School of Information Systems and Technology Management at the University of New South Wales Business School offers us a glimpse inside the black box of machine learning with an introduction to decision trees.
What are decision trees?
Decision trees are highly versatile predictive models that allow items to be rapidly classified, grouped or valued against a range of parameters. They are also a great way to simply visualise a decision involving multiple factors.
Like a high-tech game of 20 questions, decision trees are collections of 'if this, then that' rules which, with the right training and input data, can produce highly accurate and informed predictions or decisions, in the blink of an eye.
“Decision trees are collections of 'if then' rules that you can then imagine connect the branches of a tree. If you have a lot of input data, you can follow a range of 'if/then' rules to go down different splits of branches to end up at a leaf, which is an outcome or reasonable prediction of a target variable,” Dr Kirshner explained.
For example, a simple decision tree could be used to help prospective students decide whether they should commence their university studies online or on campus.
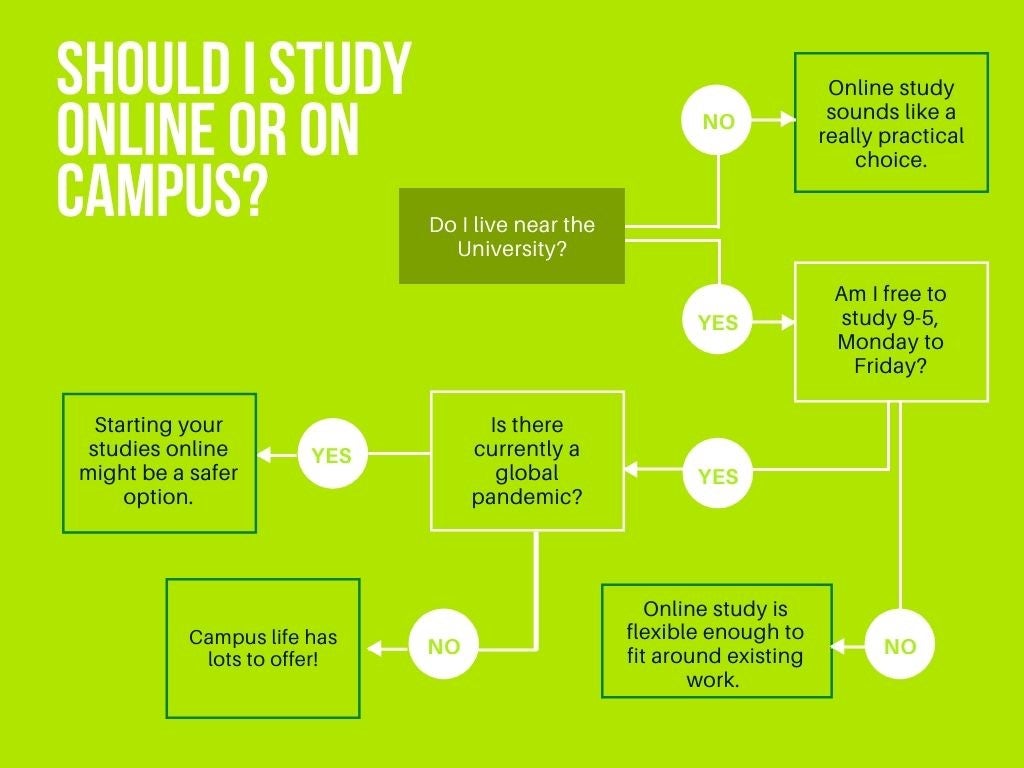
Components of a decision tree
Decision trees are made up of three elements: nodes, branches and leaves.
- Root nodes contain the overarching question or the decision your tree is seeking to answer.
- Branches indicated by an arrow line, represent options, criteria or courses of action
- Leaf nodes which appear at the end of branches represent either a further question to be asked (decision node), outcome (end node) or probability / uncertainty of an outcome (chance / change node).
Types of decision trees
Decision trees can be used to make two different kinds of predictions using classification (grouping and typifying) or regression (valuing and weighting).
“The main difference between a classification tree and regression tree is whether the prediction that you are making is a category as in the case of a classification tree or whether the outcome is a continuous value as in the case of a regression tree,” Dr Kirshner explained.
- Classification model decision trees are used to group and categorise data in ways that makes predictions about their type. For example, based on a range of personal attributes like location, work requirements and risk factors would it be better for a student to study on campus or online?
- Regression model decision trees are used to find or estimate a real or continuous value and typically relies on weightings for various inputs. To stick with the student example, a regression tree model could be created to calculate the overall benefit of further study including fees and expenses and a range of intangible benefits to weigh the cost of taking time out of the workplace against potential future opportunities.
Decision trees in machine learning
Decisions trees are literally everywhere.
“At this point, almost all areas and industries are using predictive analytics involving decision trees,” Dr Kirshner said. “Not only are they an amazingly useful tool, for me it's their interoperability that makes them really popular amongst data scientists,” he said.
For professionals looking to build advanced capability in machine learning, modelling and predictive analytics, UNSW Online’s Master of Data Science builds the technical skills needed to work with complex data and drive real-world outcomes.
If you've ever applied for a loan or insurance or tried to sell a property you've probably had the experience of being categorised by one. For example, when applying for a loan, your personal debt, earning capacity, credit history, age and savings will all effect the likelihood of you getting the loan you want based on how likely you are (statistically speaking) to default. Similarly, when valuing a property for sale, input data such as location, land area, number of rooms, views and similar properties sold in the area will all inform the expected price range.
Although slightly less obvious, decision trees are also widely used in online marketing to show us a range of products, songs or even prospective romantic partners we are likely to be interested in based on our internet browsing or purchase histories.
Study business analytics 100% online at UNSW
Benefits of decision trees
Decision trees have become a popular choice for predictive modelling in machine learning for a number of reasons, mostly due to their simplicity – which makes them transparent and fast.
As well as being a Senior Lecturer at University of New South Wales Business School, Dr Kirshner is part of an Australian advisory group Ethical ai that helps organisations to ensure their AI is interoperable and ethical.
He believes that the simplicity of decision trees will offer a market advantage over extremely complex 'black-box' AI solutions which are starting to come under increasing public scrutiny.
“Unlike most models, decision trees are highly visual and that makes it easy for data scientists to easily convey the underlying logic of the model to all kinds of stakeholders from executives to the general public,” he said.
“Simple, classification decision trees often require less data prep, are better at handling non-linear data and can perform feature selection and automatically screen out useless variables.
“A lot more has to go into it if you're using regression models. Understanding weightings requires greater background knowledge in math and statistics where simple decision trees don't.”
Thanks to their speed, decision trees can also be very useful in a crisis. Whether that's trying to match the right advert to a reader on your website before they click away or a split-second decision that could be a matter of life and death on the emergency ward. Though you may not be aware of it, machine learning has been helping fatigued doctors save lives for several decades already.
Machine learning and COVID-19
“Decisions trees are being used widely right now to help combat COVID-19,” Dr Kirshner said. “They're being used to improve testing and rapidly perform risk and severity assessments which are traditionally very labour-intensive tasks.”
The fact they don't take a lot of processing time makes them a perfect choice for real-time analytics and decision making. With the high volume of COVID-19 patients, there would otherwise be delayed analysis and treatment.
“Data from blood samples can be used to assess the probability of having more severe forms of the disease and more efficiently allocate hospital resources,” Dr Kirshner said. “They're also being used to help people self-diagnose and asses their own risk profiles to help them decide whether they need to come in for testing.”
It's possible you've recently encountered a decision tree that looks something like this:

Learning to trust machines
There is substantial evidence that decision trees are better at some tasks than human doctors, but not everyone is on board with leaving crucial decisions to machines.
“In the 1970s, a cardiologist by the name of Goldman created a very simple decision tree to predict heart attacks,” Dr Kirshner said.
Goldman's chest pain protocol looked at ECG (electrocardiogram) tests and used three questions to rapidly asses the urgency of anyone reporting symptoms of chest pain:
- Is the pain felt by the patient unstable angina?
- Is there fluid in the patient's lungs?
- Is the patients diastolic blood pressure below 100?
Patients with all three criteria were at highest risk, with two factors qualifying for cardiac care and negative to all three as low risk for heart attack.
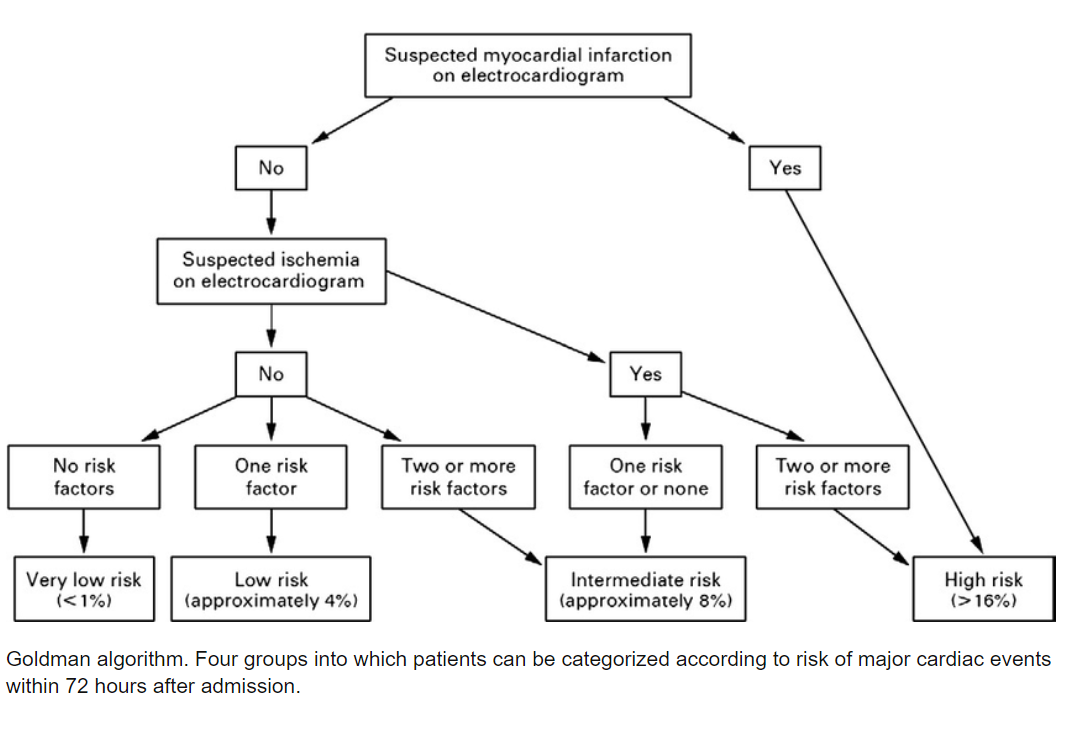
Assessing heart attack cases manually was slow going and even though delays could be deadly, people had an aversion to relying on AI,” Dr Kirshner explained. It wasn't until decades later that the model became more widely accepted.
In the 1990's Goldman's model was tested for two years in a severely underfunded hospital in Chicago. They found Goldman's algorithm to be 70% better than hospital doctors at predicting which patients needed immediate transfer to the coronary unit, providing an accurate assessment 95% of the time.
In 2001, the Cook County Hospital in Chicago became the first to exclusively use decision trees to diagnose chest pain.
Why did it take several decades to adopt this life-saving technology? A little phenomenon known as algorithm aversion.
“Even if the algorithm might be superior to human analysis and be better at reading symptoms and detecting potential diseases, people aren't always willing to trust in it,” Dr Kirshner explained.
“One of the biggest drivers of whether or not people are comfortable using AI, is consequentiality – the more important the decision or outcome, the more likely people are to going to want to go with the human rather than machine and similarly, the more objective or trivial the task is the more likely they will be comfortable going with a machine choice.”
Although machines might be better and faster than humans at many things it's a good idea to look at them critically and understand their limitations.
Limitations and risks of decision trees in machine learning
“The greatest challenge with machine learning and AI in corporate decision trees is in ensuring it's ethical use,” Dr Kirshner said. “Decision trees can be great for pursuing hard goals, but by nature this efficiency can also make them myopic.”
“Algorithms are also increasingly interacting with and learning from each-other which makes it even more difficult to ascertain whether outcomes are equitable and fair.”
It's been found that without human interference, knowledge or programming, ecommerce price setting algorithms, which are designed to maximise the organisations revenue can participate in collusion, and price fixing, driving up prices by learning about the pricing of competitors.
There are also plenty of cases of black-box solutions causing problems or perpetuating social inequalities like race and gender. For example, science career ads are disproportionately shown to men (despite it being illegal to target jobs to one gender) and facial recognition software struggles to recognise darker skin tones misidentifying people with dark skin 5-10 time more often than white people.
MIT researcher Catherine Tucker recently found that the black-box design of Facebook's Advertising tools created automated barriers to the promotion of opportunities in STEM (science technology, engineering and math) to women.
Tucker designed a Facebook advert for STEM to be shown to men and women in a number of countries with bids increasing if country targets weren't met. Although the campaign design seemed equitable, the outcomes were not. The advertisement for STEM was shown to a disproportionally higher number of males.
This wasn't because men were more interested in the subject areas than women. In fact, women had higher click-through rates on the advert. So why the discrepancy?
The bias was eventually linked back to Facebooks automated bidding process. Young females between the ages of 18 and 35 are one of the most important demographics for marketers online, a 'goldmine' demographic. And in Facebooks automated bidding structure, the cost of reaching them over the competition is therefore, much higher.
And there was no way to know that from the way Facebook sets up their black box system.
This is just one of many examples of machine learning indirectly perpetuating inequality. Part of the problem is that decision trees can only be as socially aware as their designers.
According to Dr Kirshner, recent legislation from the Australian Human Rights Commission is about to make this a pretty big deal:
“New guidelines make it mandatory that AI and machine learning not be the cause of any kind of unfair discrimination against individuals and the companies that create them can now be held to account for any unjust outcomes,” he said.
“Organisations are going to have to really understand and be accountable for their models,” he said. “Working with models that are readily interoperable, like decision trees, will become even more important moving forward,” Dr Kirshner said
Interested in the impact of machine learning on the future of work? Study online with Dr Sam Kirshner
Tips for building better decision trees
Whether you code or rely on (and are accountable for) decision tree models in a managerial context, it's important to evaluate and review them on a regular basis.
1. Design with soft goals in mind
In any form of Machine learning, fair outcomes depend on your design and data being free of bias. Without accounting for soft goals, algorithms will just act myopically towards tangible hard goals like profit scales and click through rates.
”Modelers and designers have to be explicit about the objectives of the decision tree, it can mean incorporating or quantifying soft goals like quality or representation into the algorithm,” Dr Kirshner said.
2. Choose the right decision tree algorithm(s)
Depending on their goals, modelers can choose from a range (or combination) of decision algorithms. Popular choices include CART, ID3 and C4.5 which each have slightly different uses.
CART
CART which stands for 'classification and regression tree' is the most basic or original decision tree algorithm. The advantage of CART is that is focuses on binary splits (where branches can only be split by a single condition). Their simplicity makes them faster to calculate than other models but can also result in longer (and more difficult to read) trees.
To measure success or error rates, CART uses a "Gini index" which measures how often a randomly chosen element from a set would be incorrectly labelled. They're ideal for lower risk calculations that need to be done in real time like online shopping or music suggestions.
ID3 and C4.5
ID3 and C4.5 are slightly more complicated decisions trees in that they allow for multiple-way splits in the tree. For example, in a game of 20 questions designed to identify a person in a room, these algorithms might be able to ask whether their hair colour is 'blond, brunette, red, grey or other' while CERT could only ask 'Are they blonde?' with a yes no answer as a result.
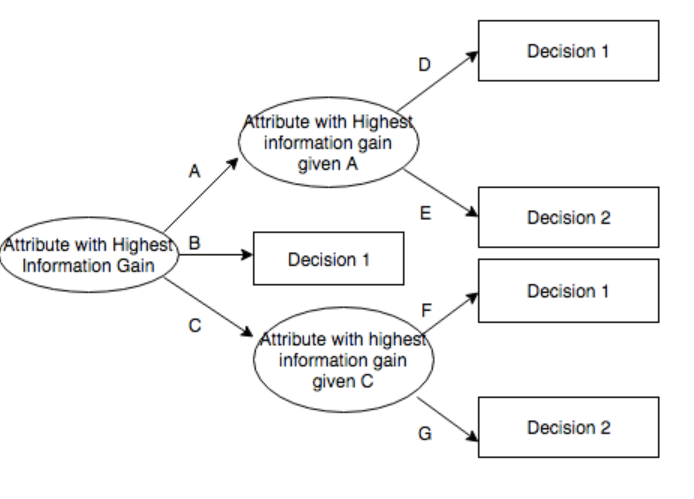
Instead of a Gini index, ID3 and C4.5 use entropy (a measurement capturing (the lack) information)) to test their models.
The main difference between ID3 and C4.5 is that ID3 only considers splits which are categorical or fixed, while 4.5 is slightly more dynamic and can allow partitioning to happen with continuous attributes using greater sets of intervals.
Broadly speaking, ID3 and C4.5 lend themselves to more highly specific tasks that require a great level of certainty than CART and can afford to compromise slightly on speed - such as medical diagnostics or economic modelling.
Random forests
To reduce the likelihood of error from overfitting or bias, modelers might prefer not to rely on a single decision tree. Random forests are what's called an ensemble model that combines lots of decision trees together into a single predictive model. In random forest algorithms, each tree receives a 'vote' on the outcome and the sum of the outcomes then becomes the prediction. Random forests can also work with random subsets of data to help create diversity, identify bias and improve accuracy.
3. Review your training data
Models can only be as good as the data they have to work with. “More-so that fine tuning your model parameters like the maximum depth of your tree, higher quality data can lead to substantially better performance,” Dr Kirshner said.
Work with subject matter experts to make sure you really understand the data and check that your data is sufficiently balanced before creating your tree. If the data your tree is trained on is dominated by a specific outcome, you will run into problems.
The diversity of samples you use to train your models on can make a big difference to ethical outcomes as well.
“Data variety is really important,” he said. “A good example might be health inspectors relying on historical data to select restaurants that are likely to have health code violations.”
“An algorithm with a hard goal of finding more violations and working with an historic data set might more often select restaurant in low-income neighbourhoods already on record for violations.
“For fairness, modelers might set upper limits to constrain the number of inspections in a certain neighbourhood, or augment their historical data with another source such as Yelp or Trip Advisor data, with crowdsourced comments they would get a much larger and more diverse perspective than their internal records and possibly help identify bias in your internal data set,” Dr Kirshner said.
4. Prune your trees thoroughly
Pruning refers to the process of reviewing and editing your decision tree. This involves methodically removing and testing the efficacy of various branches to see which ones provide limited additional predictive value.
There is always a trade-off between accuracy and speed, but unpruned trees can become overly complex and unruly. Where possible you want to collapse those branches into a single tree to make it easier to read, faster to process and reduce your chance of overfitting (creating noise in your data results by being too specific)
5. Sense check your model with someone non-technical
It's important to check your tree for interoperability and transparency. “One of the tips I give my students is to try to explain the logic of their models to someone less technically literate. If your non-technical or less mathematically literate friends can't understand the tree, it's probably not a good model,” Dr Kirshner said.
This is particularly important for algorithms with a human element or outcomes that might directly or indirectly affect people's lives.
Interested in starting a career in analytics?
UNSW Online offers professionals from a wide variety of backgrounds an opportunity to upgrade their qualifications to specialise in analytics. The Master of Analytics have been designed for graduates of undergraduate courses in IT, engineering, maths, statistics and a number of other disciplines.
Categories



