 1300 974 990 | Australia |
1300 974 990 | Australia | 
Machine learning technology has made major advancements over the last ten years, turning concepts that were previously relegated to science fiction into real-life applications. But this progress isn’t the result of a single innovation in how to teach machines, it represents the combined achievements of many different approaches to the discipline. In this article, we’ll discuss the four machine learning concepts that sit at the heart of machine learning: supervised learning, unsupervised learning, deep learning, and reinforcement learning.
Machine Learning – a brief review
While there are a variety of different machine learning techniques in existence, they all require the use of an algorithm that allows a machine to ingest and learn from outside data. After that initial learning process is complete, the trained machine can use what it’s learned to make judgments about the data it was designed to analyse.
For example, a data scientist could train a machine to identify photographs of dogs and cats by “showing” it many photographs of dogs and cats, along with a label (“dog” or “cat”) for each photograph. When the trained machine is asked to determine whether a new image is of a dog or a cat, it will decide by comparing the new image against what it knows about dog and cat photographs. The confidence with which the machine can predict whether a new photograph is of a cat or a dog depends on how similar the new photograph is to the photographs that it was trained on.
This type of machine is very simple, and can only perform the single task of categorising photographs as “dog” or “cat”. It doesn’t have the ability to decide that a photograph is neither a cat nor a dog. If you were to show it a photograph of a banana, it would still predict that the photograph is either a cat or a dog, because those are the only two categories it knows.
Supervised learning
The specific dog-cat example discussed above is an example of a supervised learning technique. Supervised learning is a type of machine learning in which all the data used to teach a machine is labelled, in this case, either “dog” or “cat”. Supervised machine learning was initially developed as a form of “classical” machine learning, which refers to forms of machine learning that rely on data scientists to develop a task-specific algorithm for every function they want the machine to do.
Because they rely on sets of discrete, clearly-labelled data, supervised learning programs are very effective for applications that involve clearly defined variables. For instance, a supervised learning program might explore how population demographics (e.g., income, ethnicity, education, etc) predict survival rates for a certain disease. Further, because all of the data they use is labelled, it’s easy to follow the logic of supervised learning programs to better understand the insights that their predictions generate.
Unsupervised learning
Unsupervised learning is used to teach machines to learn from unlabelled data. If you were to train a program to recognise the difference between dog and cat photographs, but could only do so using photographs that aren’t labelled “dog” or “cat”, an unsupervised learning algorithm would be necessary to complete the training process. Unsupervised learning, like supervised learning, was initially developed as a form of classical machine learning.
Unsupervised machine learning algorithms work by figuring out different ways to divide unlabelled data into different groups, such as fur colour, photograph composition, or species (dog/cat). As these groupings are based on unlabelled data, the groups themselves are also unlabelled; however, a data scientist can simply look at the data contained in the different groupings in order to identify the grouping that contains the features they’re interested in.
If an unsupervised learning program designed to identify dog and cat photographs was shown a photograph of a banana, it could avoid categorising the photograph as a dog or cat, because the photograph would not be similar enough to either group to be classified as belonging to one of them. This robustness against error makes unsupervised learning great for tasks in which a machine may encounter unexpected data that falls outside of the categories it was designed to handle.

Deep learning
Classical approaches to unsupervised and supervised learning revolve around the use of task-specific algorithms and require the data scientist to specify what features of the data the machine should learn from (e.g., fur colour). In contrast, deep learning programs self-calculate what features of the data are most important to learn from as part of the training process—the data scientist doesn’t tell the machine what to pay attention to.
Deep learning architectures can utilise both supervised and unsupervised machine learning techniques. In fact, both the supervised and unsupervised learning examples discussed above would use deep learning, rather than a classical approach to machine learning. Photographs are extremely complex and varied; to distinguish between dogs and cats using classical machine learning, a data scientist would have to manually develop a set of criteria to distinguish dog and cat photographs and figure out how to identify that criteria in mathematical terms.
A deep learning machine doesn’t need to be told which features are important to distinguish between a dog or a cat; it can instead figure those things out for itself by processing each image into an abstract set of features and calculating which of them are most important to the image identification process. These features will typically be things that matter to computers but which go unnoticed by human observers, such as the mathematical relationships between certain pixels in a photograph.
Deep learning: neural networks
The “artificial neural network” (ANN) is one of the most common deep learning architectures, so-called because its design is inspired by the relationship between neurons in the brain. ANNs are composed of an input layer, which receives data (dog and cat images) from the data scientist; of one or more “hidden layers”, which is where the machine identifies features of interest; and of an output layer, which returns the results from the hidden layer back to the data scientist (e.g. “is the image of a dog or a cat”).
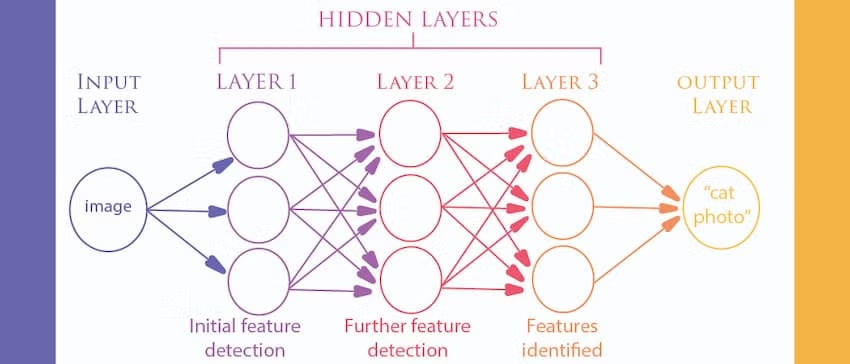
Deep learning is an extremely powerful form of machine learning and is utilised for most complex machine learning activities—such as voice control and image recognition—where the number of features involved is too complex to be described by a human. Classical machine learning techniques are still used in a variety of situations, but the accuracy and efficiency of deep learning make it the go-to method for more complex functions.
Reinforcement learning
The methods described above all rely on a data scientist to feed a machine information (data) in order to train it to do a desired task. But what if there’s no data available for a machine to learn from? That’s when reinforcement learning becomes necessary.
Reinforcement learning works in scenarios in which the data scientist can describe a starting point, an objective, and a way to get from one to the other (i.e., an environment). Google’s AlphaGo program, which was able to beat a grandmaster at the East Asian board game Go, used reinforcement learning to figure out how to play and master the game. For AlphaGo, the starting point is the initial board game setup, the objective is to win the game, and the environment is the game board and rules.
Approaches to reinforcement learning utilise simulations to discover the best way to get from a starting point to an objective. The machine learns through positive and negative reinforcement so that simulated actions which lead to poor results are less likely to be chosen again. Reinforcement-learning machines may also be able to continue learning after their initial training, allowing them to become smarter the more they are used.
Data scientists are currently using reinforcement learning to teach self-driving vehicles how to navigate safely on the road; however, the technology is not yet sophisticated enough to produce an autonomous car that can operate safely enough for regular consumer use.
Machine learning techniques continue to advance
Every day, data scientists around the world are experimenting with and developing new techniques for deep, classical, and reinforcement learning. Their innovations continue to advance the capability of machines to interact with their environment without direct human oversight.
The University of New South Wales’ data science program includes a heavy focus on machine learning, making them an excellent choice for anyone seeking to contribute to the development of the field. UNSW’s online data science programs include masters, graduate diploma and graduate certificate programs, and provide a flexible option for anyone looking to break into the field.
Moreover, UNSW is globally ranked as a top university in mathematics, statistics, economics, and computer science—the core subjects that power the data science profession. From the discovery of new breakthroughs in medical research to the prevention of financial fraud, there are no limits to the impacts that machine learning can allow you to make.
Categories



